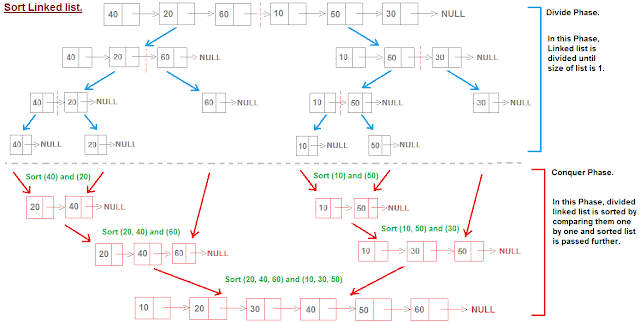
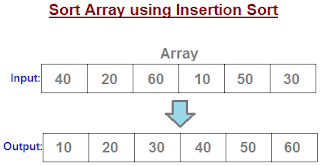
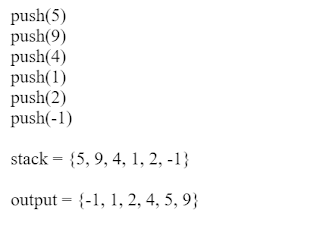We are using the HashMap to store the character as key and count
of times it is repeated as value.
package com.string.codebyakram;
import java.util.HashMap;
public class NonReapingCahr {
public static void main(String[] args) {
String string = "hello";
System.out.println(findNonReapingCahr(string));
}
public static char findNonReapingCahr(String string) {
HashMap< character > countChar = new HashMap<>();
for (int i = 0; i < string.length(); i++) {
int count = countChar.get(string.charAt(i)) == null ? 1 : countChar.get(string.charAt(i)) + 1;
countChar.put(string.charAt(i), count);
}
for (int i = 0; i < string.length(); i++) {
if (countChar.get(string.charAt(i)) == 1) {
return string.charAt(i);
}
}
return '\0';
}
}